22 Jul 2022
 The Law of Demeter essentially says that each unit should only talk to its ‘immediate friends’ or ‘immediate dependencies’, and in spirit, it is pointing to the principle that each unit only have the information it needs to meet its purpose. In that spirit, the Law of Demeter takes two forms that are relevant to making your code more testable: (1) object chains, and (2) fat parameters.
The Law of Demeter essentially says that each unit should only talk to its ‘immediate friends’ or ‘immediate dependencies’, and in spirit, it is pointing to the principle that each unit only have the information it needs to meet its purpose. In that spirit, the Law of Demeter takes two forms that are relevant to making your code more testable: (1) object chains, and (2) fat parameters.
Object Chains
This is the more classic violation of the Law of Demeter. This happens when a class C has a dependency D, and D has method m that returns an instance of another class A. The violation happens when C accesses A and calls a method in A. Note that only D is the ‘immediate’ collaborator/dependency of C, and not A. The Law of Demeter says that C should not be accessing the method in A.
# A violation of the Law of Demeter looks as follows.
## Example 1:
c.d.m().methodInA()
## Example 2:
d: D = c.d
a: A = d.m()
a.methodInA()
What is the problem with violating the Law of Demeter? Consider the following production code:
class UpdateKVStore:
def __init__(self, client: KVStoreClient) -> None:
self.client = client
def update_value(new_content: Content) -> Status:
transaction: KVStoreClient.Transaction = self.client.new_transaction()
if transaction.get_content() == new_content:
# Nothing to update
transaction.end()
return Status.SUCCESS_UNCHANGED
mutation_request: KVStoreClient.MutationRequest = (
transaction.mutation_request().set_content(new_content)
)
mutation = mutation_request.prepare()
status: KVStoreClient.Mutation = mutation.land()
return status
Now how would you unit test this? The test doubles for testing this code will look something like this
mock_client = MagicMock(spec=KVStoreClient)
mock_transaction = MagicMock(spec=KVStoreClient.Transaction)
mock_mutation_request = MagicMock(spec=KVStoreClient.MutationRequest)
mock_mutation = MagicMock(spec=KVStoreClient.Mutation)
mock_client.new_transaction.return_value = mock_transaction
mock_transaction.mutation_request.return_value = mock_mutation_request
mock_mutation_request.prepare.return_value = mock_mutation
Now you can see how much the class UpdateKVStore and its unit tests need to know about the internals of the KVStoreClient. Any changes to how the KVStoreClient implements the transaction will cascade into test failures on all its clients! That’s a recipe for a low accuracy test suite.
There are a few ways to address this. Instead, if KVStoreClient could be recast as a Transaction factory, and then encapsulate all operations associated with the transactions within the Transaction class, then UpdateKVStore can be modified as follows:
class UpdateKVStore:
def __init__(self, client: KVStoreClient) -> None:
self.client = client # Now a Factory class for Transaction.
def update_value(new_content: Content) -> Status:
transaction: KVStoreClient.Transaction = self.client.new_transaction()
if transaction.get_content() == new_content:
# Nothing to update
transaction.end()
return Status.SUCCESS_UNCHANGED
status = transaction.update_and_land(new_content)
return status
When testing the new UpdateKVStore, you only need to replace the KVStoreClient and the Transaction, both of which are (explicit or implicit) direct dependencies, with test doubles. This makes the code much easier and straightforward to test.
Fat Parameters
While the anti-pattern of ‘fat parameters’ does follow directly from the Law of Demeter, it does follow from the spirit of passing in only the information that the class needs to perform its function. So, what are fat parameters? They are data objects that as passed in as an argument to a class, and they contain more information than what is needed by the class.
For instance, say you have a class EmailDispatcher whose method setRecipient only needs a customer name and email address. The method signature for setRecipient should only require the name and email, and not the entire Customer object that contains a whole lot more.
@dataclass(frozen=True)
class Customer:
... # data class members.
def getFullName(self):
...
def getEmail(self):
...
def getPhysicalAddress(self):
...
def getPostalCode(self):
...
def getCountry(self):
...
def getState(self):
...
def getCustomerId(self):
...
# and so on.
class EmailDispatcher:
...
def setRecipient(name: str, email: str):
...
def setRecipientWithFatParameter(customer: Customer):
...
def sendMessage(self, message: Message):
...
In the pseudocode above, the class EmailDispatcher has two methods setRecipient and setRecipientWithFatParameter. The former uses only the information it needs, and the latter passed in the entire Customer object as a fat parameter.
The convenience of passing in the entire Customer object is straightforward. It allows gives you a simple method signature. It makes it easier for the method to evolve to use richer information about the customer without needing to change its API contract. It allows you to define a common Dispatcher interface with multiple Dispatchers that use different properties of the Customer class.
However, when it comes to unit testing, such fat parameters present a problem. Consider how you would test the EmailDispatcher’s setRecipientWithFatParameter method. The tests will need to create fake Customer objects. So, your fake Customers might look like this:
fakeCustomer = Customer(
first_name="bob",
last_name="marley",
email="bob@doobie.com",
address=Address(
"420 High St.",
"",
"Mary Jane",
"Ganga Nation",
"7232"
),
id=12345,
postal_code="7232",
...
)
When someone reads this unit test, do they know what is relevant here? Does it matter that the second parameter of address is empty string? Should the last parameter of address match the value of postal_code? While we might be able to guess it in this case, it gets more confusing in cases where the fat parameter is encapsulating a much more complicated entity, such as a database table.
When refactoring or making changes to the EmailDispatcher, if the unit test fails, then figuring out why the test failed becomes a non-trivial exercise, and could end up slowing you down a lot more than you expected. All this just leads to high maintenance costs for tests, low readability , poor DevX, and limited benefits.
11 Jul 2022
 You service may be massive, but it’s public API surface is pretty small; it has just a handful of APIs/endpoints. Everything else behind those APIs are ‘private’ and ‘implementation details’. It is highly advisable to follow this pattern even when designing the implementation of your service, almost like a fractal. This will pay dividends in the quality of your test suite.
You service may be massive, but it’s public API surface is pretty small; it has just a handful of APIs/endpoints. Everything else behind those APIs are ‘private’ and ‘implementation details’. It is highly advisable to follow this pattern even when designing the implementation of your service, almost like a fractal. This will pay dividends in the quality of your test suite.
For instance, you service implementation should be split into ‘modules’ where each module has a well defined API through which other modules interact with it. This API boundary has to be strict. Avoid the temptation of breaking this abstraction because your module need this ‘one tiny bit’ of information that is available inside the implementation of another module. You will regret breaking encapsulation, I guarantee it!
If you follow this pattern, you will eventually reach a class that has a public API, has all of its external/shared dependencies shared, and delegates a lot of it’s business logic and complex computation to multiple ‘private’ classes that are practically hermetic and have no external/shared dependencies. At this point, treat all these ‘private’ classes as, well, private. That is, DO NOT WRITE UNIT TESTS FOR SUCH CLASSES!
Yes, that statement seems to fly in the face of all things sane about software testing, but it is a sane statement, nonetheless. These private classes should be tested indirectly via unit tests for the public class that they serve/support. This will make your tests a lot more accurate. Let me explain.
Say, you have a public class CallMe and it uses a private class HideMe, and furthermore, HideMe is used only by CallMe, and the software design enforces this restriction. Assume that both CallMe and HideMe have their own unit tests, and the tests do an excellent job. At this point, there is a new requirement that necessitates that we refactor CallMe’s implementation, and as part of that refactoring, we need to modify the API contract between CallMe and HideMe. Since HideMe’s only caller is CallMe, it is completely safe to treat this API contract as an implementation detail and modify it as we see fit. Since we are modifying the specification of HideMe, we have to change the tests for HideMe as well.
Now, you run the tests, and the tests for HideMe fail. What information does that give you? Does that mean that there is a bug in HideMe; or does it mean that we did not modify the tests correctly? You cannot determine this until you either manually inspect HideMe’s test code, or until you run the tests for CallMe. If CallMe’s tests fail, then (since this is a refactoring diff) there must be a bug in HideMe and/or CallMe, but if the tests don’t fail, then it must be an issue in HideMe’s tests.
Thus, it turns out that the failure in HideMe tests gives you no additional information compared to failure in CallMe’s tests. Thus, tests for HideMe have zero benefits and a non-zero maintenance cost! In other words, testing HideMe directly is useless!
By aggressively refactoring your code to push as much of you logic into private classes, you are limiting the API surface of your software that needs direct testing, and simultaneously, ensuring that your tests suite is not too large, has very high accuracy, with reasonable completeness.
03 Jul 2022
 Almost by definition unit tests should be isolated from its (external, shared) dependencies. But, equally importantly, unit tests should also be isolated from each other. When one test starts to affect another test, the two tests are said to be coupled. Alternatively, if changes to one test can negatively impact the correctness of another test, then the two tests are said to be coupled.
Almost by definition unit tests should be isolated from its (external, shared) dependencies. But, equally importantly, unit tests should also be isolated from each other. When one test starts to affect another test, the two tests are said to be coupled. Alternatively, if changes to one test can negatively impact the correctness of another test, then the two tests are said to be coupled.
Coupled tests are problematic in two ways.
- Tests become less readable. Reading the code for a single unit test does not necessarily communicate what the test does. We also need to understand the ‘coupling’ between that test and other tests to grok what a single test does. This coupling can be subtle and not easy to follow.
- Tests become less accurate. When one test affects another, it becomes difficult to make changes to a single test in isolation. For instance, if a diff makes changes to the some production and test code, and then a test fails, then it is not always clear why the test failed. The failure could due to a bug, or an artifact the coupled tests. Thus, your tests are no longer trustworthy, and therefore, less accurate.
Coupling can happen in many ways. The obvious ones include (1) using the same shared dependency (like when you use the same temp file name in all tests), and (2) relying on the post-condition of one test as a precondition of another test. Such cases are also obvious to detect, and to fix. There are two more following ways in which tests can be coupled; but these are more subtle, and more prevalent.
- Precondition setting in test fixtures
- Parameterized tests for heterogeneous tests
The rest of this note is focused on the above two anti-patterns of test coupling.
Coupling through test fixtures
Say, your SUT has a dependency called Helper, and initially, for the two tests in your unit tests for the SUT, you initialize your Helper stub with contents valueA, and valueB. Since both tests share the same initial state, you include the initialization code in the SetUp of the unit tests.
class SUTTestCase(unittest.TestCase):
def setUp(self):
self.helper = StubHelper()
self.helper.add_contents([valueA, valueB])
self.sut = SUT(self.helper)
def test_behavior1(self) -> None:
... # Assumes self.helper set with contents=[valueA, valueB]
def test_behavior2(self) -> None:
... # Assumes self.helper set with contents=[valueA, valueB]
Next, you modify SUT to add features to it. In order to test those features, the Helper stub needs to include controllerA. But these are useful only in the new tests being added. However, looking at the unit test you already have, it is easiest to to simply add controllerA to self.helper. So, your unit tests look as follows:
class SUTTestCase(unittest.TestCase):
def setUp(self):
self.helper = StubHelper()
self.helper.add_contents([valueA, valueB])
self.helper.add_controller(controllerA)
self.sut = SUT(self.helper)
def test_behavior1(self) -> None:
... # Assumes self.helper set with contents=[valueA, valueB]
# But this test assumes nothing about self.helper's controller
def test_behavior2(self) -> None:
... # Assumes self.helper set with contents=[valueA, valueB]
# But this test assumes nothing about self.helper's controller
def test_behavior3(self) -> None:
... # Assumes self.helper set with contents=[valueA, valueB], and controller=controllerA
def test_behavior4(self) -> None:
... # Assumes self.helper set with contents=[valueA, valueB], and controller=controllerA
Then you discover a gap in testing that requires the initial state of the Helper stub to have just the content valueA and include controllerA. Now, when adding this new unit test to suite, the simplest way to do this would be to remove valueB from self.helper at the start of the new test. So, now, your test suite looks as follows:
class SUTTestCase(unittest.TestCase):
def setUp(self):
self.helper = StubHelper()
self.helper.add_contents([valueA, valueB])
self.helper.add_controller(controllerA)
self.sut = SUT(self.helper)
def test_behavior1(self) -> None:
... # Assumes self.helper set with contents=[valueA, valueB]
# But this test assumes nothing about self.helper's controller
def test_behavior2(self) -> None:
... # Assumes self.helper set with contents=[valueA, valueB]
# But this test assumes nothing about self.helper's controller
def test_behavior3(self) -> None:
... # Assumes self.helper set with contents=[valueA, valueB], and controller=controllerA
def test_behavior4(self) -> None:
... # Assumes self.helper set with contents=[valueA, valueB], and controller=controllerA
def test_behavior5(self) -> None:
# Assumes self.helper set with contents=[valueA, valueB] (because of other tests' setup)
self.helper.remove_content(valueB)
# Now assumes self.helper set with contents=[valueA]
...
Let pause here and inspect the state of the unit test. The tests are coupled. Why? Because modifying one test ends up affecting other tests. In the example above, if we replace self.helper.add_contents([valueA, valueB]) with self.helper.add_contents(valueA) for tests test_behavior1 and test_behavior2, it will result in a failure in test_behavior5 because self.helper.remove_content(valueB) will end up throwing an error!
Furthermore, for anyone reading these tests, it is not entirely clear that test_behavior1, and test_behavior2 need self.helper to be initialized with values [valueA, valueB], but do not need for controllerA in self.helper. The preconditions for test_behavior1 and test_behavior2 are coupled with the preconditions for test_behavior3.
It also results in test incompleteness in that, if we introduce a bug that causes behavior1 to fail when self.helper.add_controller(controllerA) is not set, we might not catch that bug because we have initialized the test for behavior1 with self.helper.add_controller(controllerA).
How to decouple such tests?
Use the setUp method to simply set up your dependencies, but not to enforce any precondition. Instead, make setting preconditions part of the arrange step of each unit test. You can even encapsulate the precondition setting into a function (with the right parameters) so that the arrange section does not get too bloated, and yet the test code is readable. Consider the following refactoring of the tests:
class SUTTestCase(unittest.TestCase):
def setUp(self):
self.helper: Optional[StubHelper] = None
self.sut = SUT(self.helper)
def prepare_helper(self, contents:List[Value], controller: Optional[Controller]=None) -> None:
self.helper = StubHelper()
self.helper.add_contents(contents)
if controller:
self.helper.add_controller(controller)
def test_behavior1(self) -> None:
# Assumes self.helper is a fresh object.
self.prepare_helper(contents=[valueA, valueB])
...
def test_behavior2(self) -> None:
# Assumes self.helper is a fresh object.
self.prepare_helper(contents=[valueA, valueB])
...
def test_behavior3(self) -> None:
# Assumes self.helper is a fresh object.
self.prepare_helper(contents=[valueA, valueB], controller=controllerA)
...
def test_behavior4(self) -> None:
# Assumes self.helper is a fresh object.
self.prepare_helper(contents=[valueA, valueB], controller=controllerA)
...
def test_behavior5(self) -> None:
# Assumes self.helper is a fresh object.
self.prepare_helper(contents=[valueA], controller=controllerA)
...
Coupling in parameterized tests
Parameterized tests are a collection of tests that run the same verification, but with different inputs. While this is a very useful feature (available in almost all unit test frameworks), it is also very easy to abuse. A few common ways I have seen it abused is in conjunction with DRYing, and the use ‘if’ checks, and that often results in coupling all the tests denoted by the parameterized list. Consider the following illustration:
class TestOutput(typing.NamedTuple):
status: StatusEnum
return_value: typing.Optional[int]
exception: typing.Optional[Exception]
...
class TestSequence(unittest.TestCase):
@parameterized.expand([
[test_input1, expected_output1],
[test_input2, expected_output2],
...
])
def test_something(self, test_input: str, expected_output: TestOutput) -> None:
self._run_test(test_input, expected_output)
def _run_test(self, test_input: str, expected_output: TestOutput) -> None:
sut = SUT(...)
prepare_sut_for_tests(sut, test_input)
output = sut.do_something(test_input)
test_output = make_test_output(output, sut)
self.assertEquals(expected_output, test_output)
The above illustration tests the method do_something for various possible inputs. However, note that the outputs (as illustrated in the class TestOutput can have a status, a return_value, or an exception). This means that every instantiation (for each parameter) has to content with the possibility of different types of outputs even though any single test only should have to verify against a single type of output. This couples all the tests verifying do_something, this making it difficult to read and understand. Adding a new test case here becomes tricky because any changes to either prepare_sut_for_tests, or make_test_output now affects all the tests!
How to decouple parameterized tests?
There are some fairly straightforward ways to decouple such tests. First, is that we should be very conservative about how we organize these tests. For example, we can group all positive tests and group all negative tests separately; similarly, we can further subgroup the tests based on the type of assertions on the output. In the above example, we can have three subgroups: positive tests that verify only output status, positive tests that verify return value, and negative tests that verify exception. Thus you now have three parameterized test classes that look something like this:
class TestDoSomething(unittest.TestCase):
@parameterized.expand([
[test_status_input1, expected_status_output1],
[test_status_input2, expected_status_output2],
...
])
def test_something_status_only(
self,
test_input: str,
expected_output: StatusEnum
) -> None:
# Arrange
sut = SUT(...)
... # More 'arrange' code
# Act
output = sut.do_something(test_input)
output_status = output.status
# Assert
self.assertEquals(expected_output, output_status)
@parameterized.expand([
[test_return_value_input1, expected_return_value_output1],
[test_return_value_input2, expected_return_value_output2],
...
])
def test_something_return_value_only(
self,
test_input: str,
expected_output: int
) -> None:
# Arrange
sut = SUT(...)
... # More 'arrange' code
# Act
output = sut.do_something(test_input)
output_status = output.status
output_value = output.value
# Assert
self.assertEquals(SomeEnum.SUCCESS, output_status)
self.assertEquals(expected_output, output_value)
@parameterized.expand([
[test_return_value_input1, expected_error_code_output1],
[test_return_value_input2, expected_error_code_output2],
...
])
def test_something_throws_exception(
self,
test_input: str,
expected_error_code: int
) -> None:
# Arrange
sut = SUT(...)
... # More 'arrange' code
# Act
with self.assertRaises(SomeSUTException) as exception_context:
sut.do_something(test_input)
exception = exception_context.exception
# Assert
self.assertEquals(excepted_error_code, exception.error_code)
26 Jun 2022

Recall the two schools of thought around unit test: Detroit, and London. Briefly, the Detroit school considers a ‘unit’ of software to be tested as a ‘behavior’ that consists of one or more classes, and unit tests replace only shared and/or external dependencies with test doubles. In contrast, the London school consider a ‘unit’ to be a single class, and replaces all dependencies with test doubles.
| School |
Unit |
Isolation |
Speed |
| Detroit |
Behavior |
Replace shared and external dependencies with test doubles |
‘fast’ |
| London |
Class |
Replace all dependencies (internal, external, shared, etc.) with test doubles |
‘fast’ |
See this note for a more detailed discussion on the two schools.
Each school have it’s proponents and each school of thought has it’s advantages. I, personally, prefer the Detroit school over the London school. I have noticed that following the Detroit school has made my test suite more accurate and complete.
Improved Accuracy (when refactoring)
In the post on attributes of a unit test suite, I defined accuracy as the measure of how likely it is that a test failure denotes a bug in your diff. I have noticed that unit test suites that follow the Detroit school tended to have high accuracy when your codebase has a lot of classes that are public de jour, but private de facto.
Codebases I have worked in typically have hundreds of classes, but only a handful of those classes are actually referenced by external classes/services. Most of the classes are part of a private API that is internal to the service. Let’s take a concrete illustration. Say, there is a class Util that is used only by classes Feature1 and Feature2 within the codebase, and has no other callers; in fact, Util exists only to help classes Feature1 and Feature2 implement their respective user journies. Here although Util is a class with public methods, in reality Util really represents the common implementation details for Feature1 and Feature2.
In London
According to the London school, all unit tests for Feature1 and Fearure2 should be replacing Util with a test double. Thus, tests for Feature1 and Feature2 look as follows.
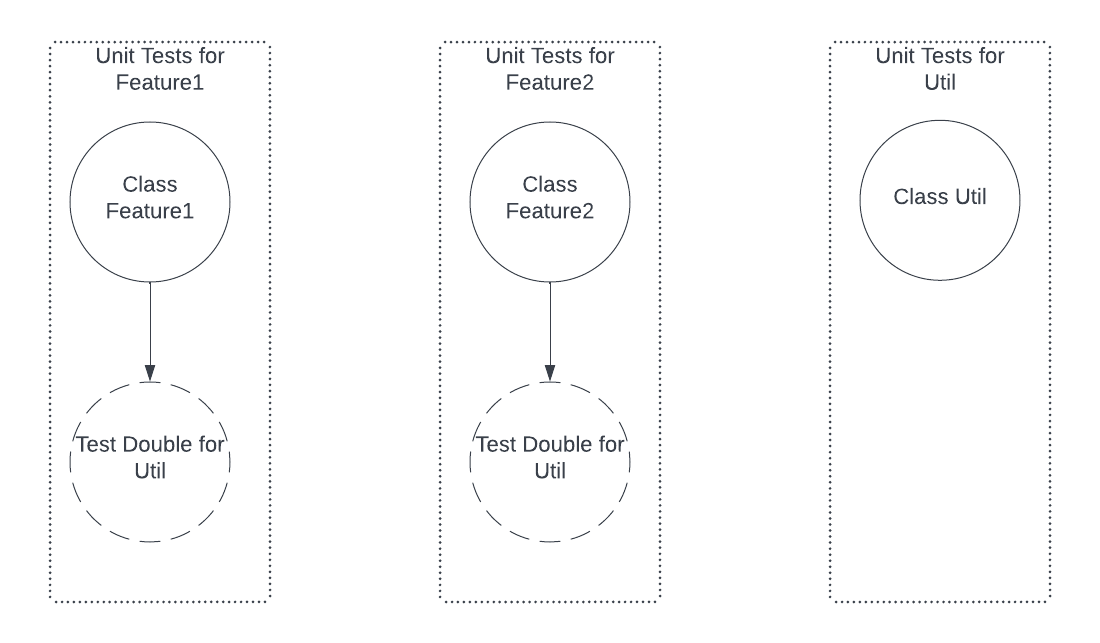
Now, say we want to do some refactoring that spans Feature1, Feature2, and Util. Since Util is really has a private API with Feature1 and Feature2, we can change the API of Util in concert with Feature1 and Feature2 in a single diff. Now, since the tests for Feature1 and Feature2 use test doubles for Util, and we have changed Util’s API, we need to change the test doubles’ implementation to match the new API. After making these changes, say, the tests for Util pass, but the tests for Feature1 fail.
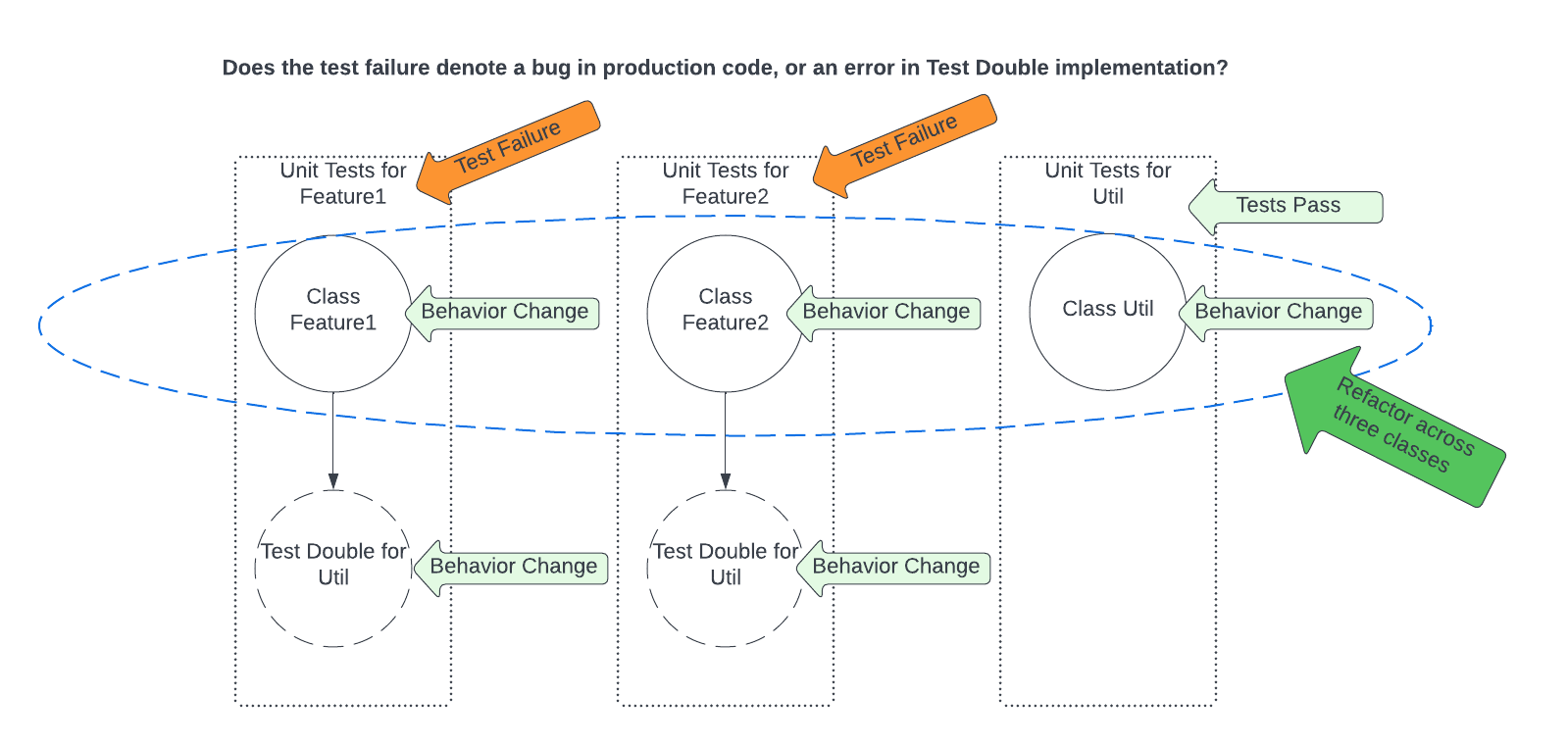
Now, does the test failure denote a bug in our refactoring, or does it denote an error in how we modified the tests? This is not easy to determine except by stepping through the tests manually. Thus, the test suite does not have high accuracy.
In Detroit
In contrast, according to the Detroit school, the unit tests for Feature1 and Feature2 can use Util as such (without test doubles). The tests for Feature1 and Feature2 look as follows.
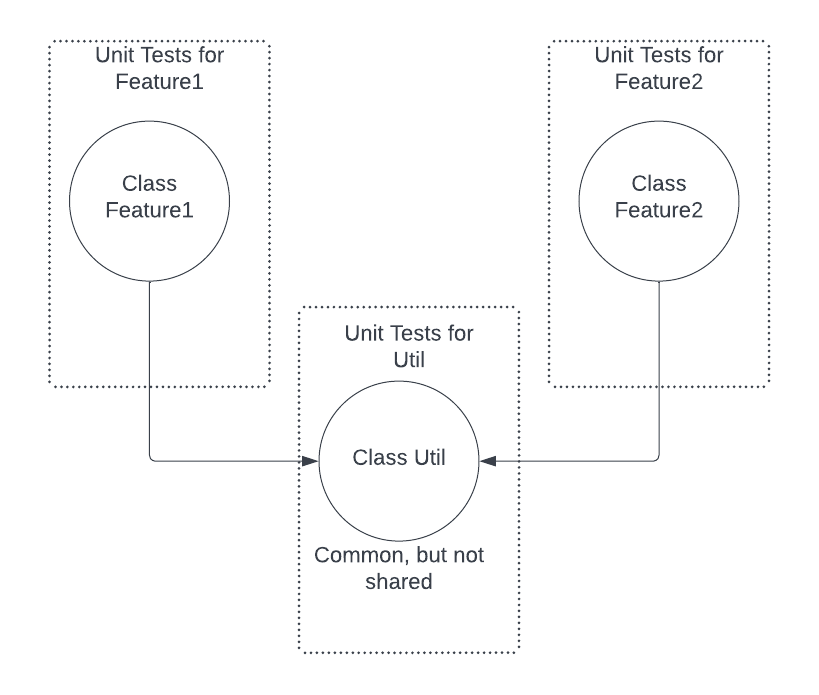
If we do the same refactoring across Feature1, Feature2, and Util classes, note that we do not need to make any changes to the tests for Feature1 and Feature2. If the tests fail, then we have a very high signal that the refactoring has a bug in it; this makes for a high accuracy test suite!

Furthermore, since Util exists only to serve Feature1 and Feature2, you can argue that Util doesn’t even need any unit tests of it’s own; the tests for Feature1 and Feature2 cover the spread!
Improved Completeness (around regressions)
In the post on attributes of a unit test suite, I defined completeness as the measure of how likely a bug introduced by your diff is caught by your test suite. I have seen unit tests following the Detroit school catching bugs/regressions more easily, especially when the bugs are introduced by API contract violations.
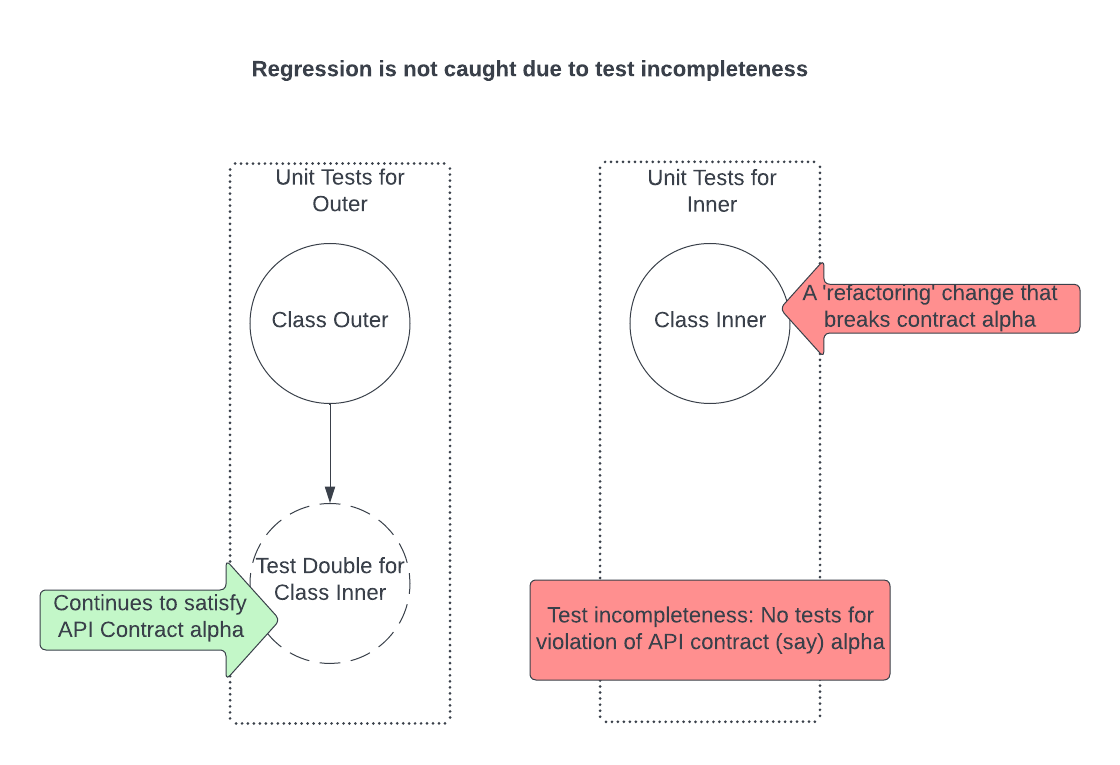
It easier to see this with an example. Say, there is a class Outer that uses a class Inner, and Inner is an internal non-shared dependency. Let’s say that the class Outer depends on a specific contract, (let’s call it) alpha, that Inner’s API satisfies, for correctness. Recall that we practically trade off between the speed of a test suite and it’s completeness, let us posit that the incompleteness here is that we do not have a test for Inner satisfying contract alpha.
In London
Following the London school, the tests for Outer replace the instance of Inner with a test double, and since the test double is a replacement for Inner, it also satisfies contract alpha. See the illustration below for clarity.

Now, let’s assume that we have a diff that ‘refactors’ Inner, but in that process, it introduces a bug that violates contract alpha. Since we have assumed an incompleteness in our test suite around contract alpha, the unit test for Inner does not catch this regression. Also, since the tests for Outer use a test double for Inner (which satisfies contract alpha), those tests do not detect this regression either.
In Detroit
If we were to follow the Detroit school instead, then the unit tests for Outer instantiate and use Inner when testing the correctness of Outer, as shown below. Note that the test incompletness w.r.t. contract alpha still exists.
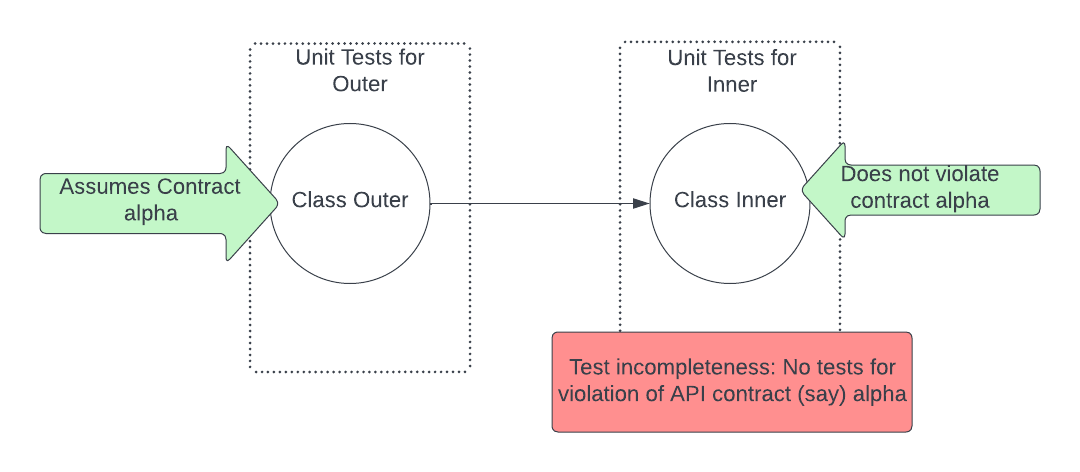
Here, like before, assume that we have a diff that ‘refactors’ Inner and breaks contract alpha. This time around, although the test suite for Inner does not catch the regression, the test suite for Outer will catch the regression. Why? Because the correctness of Outer depends on Inner satisfying contract alpha. When that contract is violated Outer fails to satisfy correctness, and is therefore, it’s unit tests fail/

In effect, even though we did not have an explicit test for contract alpha, the unit tests written according to the Detroit school tend to have better completeness than the ones written following the London school.
18 Jun 2022

Definitions: What is a unit test?
There are several definitions for unit tests. Roy Osherove defines it as “piece of code that invokes a unit of work in the system and then checks a single assumption about the behavior of that unit of work”; Kent Beck turns the idea of defining unit tests on it’s head by simply stating a list of properties, and any code that satisfies those properties in a “unit test”.
I like Vladimir Khorikov’s definition of a unit test in his book Unit Testing Principles, Practices, and Patterns. According to him, a unit test is a piece of code that (1) verifies a unit of software, (2) in isolation, and (3) quickly. The above definition only balkanizes a unit test into three undefined terms: (1) unit of software, (2) isolation, and (3) quick/fast/speed. Of the three, the third one is the easiest to understand intuitively. Being fast simply means that you should be able to run the test in real time and get the results quickly enough to enable interactive iteration of modifying the unit of software you are changing. However, the other two terms: unit of software, and isolation merit more discussion.
Are you from Detroit, or London?
In fact, there are two schools of thought around how the above two terms should be defined. The ‘original/classic/Detroit’ school, and the ‘mockist/London’ school. Not surprisingly, the school of thought you subscribe to has a significant impact on how you write unit tests. For a more detailed treatment of the two schools of thought, I suggest Martin Folwer’s excellent article on the subject of Mocks and Stubs. Chapter 2 of Khorikov’s book Unit Testing Principles, Practices, and Patterns also has some good insights into it. I have distilled their contents as it pertains to unit test definitions.
The Detroit School
The Classical or Detroit school of thought originated with Kent Beck’s “Test Driven Development”.
Unit of software. According to this school, the unit of software to test is a “behavior”. This behavior could be implemented in a single class, or a collection of classes. The important property here is that the the code that comprises the unit must be (1) internal to the software, (2) connected with each other in the dependency tree, and (3) not shared by another other part of the software.
Thus, a unit of software cannot include external entities such as databases, log servers, file systems etc. They also cannot include external (but local) libraries such as system time and timers. Importantly, it is ok to include a class that depends on another class via a private non-shared dependency.
Isolation. Given the above notion of a “unit” of software, isolation simply means that the test is not dependent on anything outside that unit of software. In practical terms, it means that a unit test needs to replace all external and shared dependencies with test doubles.
The London School
The mockist or London school of thought was popularized by Steve Freeman (twitter) and Nat Pryce in their book “Growing Object- Oriented Software, Guided by Tests”.
Unit of Software. Given the heavy bias Object-Oriented software, unsurprisingly, the unit of software for a unit test is a single class (in some cases, it can be a single method). This is strictly so. ANy other class that this the ‘class under test’ depends on cannot be part of the unit being tested.
Isolation. What follows from the above notion of a “unit” is that everything that is not the class under test must be replaced by test doubles. If you are instantiating another class inside the class under test, then you must replace that instantiation with an injected instance or a factory that can be replaced with a test double in the tests.
Here is a quick summary of the definitions of a unit tests under the two schools.
| School |
Unit |
Isolation |
Speed |
| Detroit |
Behavior |
Replace shared and external dependencies with test doubles |
‘fast’ |
| London |
Class |
Replace all dependencies (internal, external, shared, etc.) with test doubles |
‘fast’ |
What does this mean?
The school of thought you subscribe to can have a significant impact on your software design and testing. There is nothing I can say here that hasn’t already been explained by Martin Fowler in his article “Mocks aren’t stubs”. So, I highly recommend you read it for yourself.