SECURE Data Act: The dilution in pseudonymization

Disclaimer: I am not a lawyer, and this post is not advising any technical implementation in pursuit of any privacy regulation. The opinions expressed here are my own and do not represent the views of my employer.
The SECURE Data Act was introduced in Congress, and it immediately received a lot of criticism and blowback. The ACLU says it “would entirely destroy the work that states have been doing” on preemption of state privacy laws. The CDT calls out “easily exploitable loopholes” and data minimization that “lacks teeth.” Brookings notes the absence of a private right of action. EPIC calls it “a huge gift to Big Tech.” The California Privacy Protection Agency published a formal opposition letter.
As an engineer who builds privacy infrastructure, I am looking at it from a different lens. How does this bill impact the way personal data can and cannot be used for personalization? My reference is the GDPR, because I have built infra to support the regulations it mandates. Where does the SECURE Data Act diverge from GDPR, and what does that mean for how companies can use or erase user data post opt-out? The daylight between them is in pseudonymous data.
Pseudonymous data: GDPR vs. SECURE Data Act
GDPR and the SECURE Data Act define pseudonymous data in nearly identical language. Both classify it as personal data. Both require separating the identifying information. Both require technical measures to prevent attribution. You could swap one definition into the other and barely notice. While they share the definition, their treatment of pseudonymous data is very different.
Under GDPR, pseudonymous data is personal data. Period. Pseudonymization does not absolve corporations of the regulatory burden around erasure, access, profiling objections, or any obligations associated with personal data. The SECURE Data Act has a different take. Its pseudonymous data provision (Section 7(c)) suspends consumer rights for data that meets the pseudonymous threshold. The consumer cannot opt out of its use for targeted advertising. Cannot request deletion. Cannot access it. Pseudonymous data is still personal data by the bill’s own definition. The bill simply overrides the consumer’s ability to act on that fact.
The shared definition also leaves a gap. Both frameworks describe pseudonymous data in terms of records keyed by a pseudonym. But what about a derived artifact? A model trained on pseudonymous inputs, keyed by a pseudonymous identifier, encodes behavioral patterns without direct identifiers. It is linkable to an identified person if the controller holds the forward mapping, but the identifying information is “kept separately.” The bill defines personal data as information “linked or reasonably linkable” to an identified person. Neither framework cleanly resolves whether the model is pseudonymous data, personal data, or something else. The SECURE Data Act’s exemption in Section 7(c) operates on the data layer. Whether the model inherits that exemption is a question the definitions do not answer.
The divergence extends further. Under GDPR, a consumer can withdraw consent, and the controller must stop processing. Purpose limitation constrains what can be collected in the first place. The consumer has levers across the full data lifecycle: collection, processing, retention, deletion. The SECURE Data Act’s opt-out covers three specific activities: targeted advertising, sale, and certain profiling. Data collection itself is not subject to opt-out. The pipe stays open.
Data pipeline with pseudonymous data
Starting with the same behavioral data, and going through the same pseudonymization step, GDPR and the SECURE Data Act allow data controllers to offer very different treatments. Here is an example data pipeline to sharpen this difference.
One-way pseudonymizer
The SECURE Act requires two conditions for the pseudonymous exemption: the identifying information is kept separately, and appropriate technical measures ensure non-attribution. It does not specify what “appropriate” means. A one-way derivation fits cleanly: HMAC with a secret key, or a key derivation function. The forward mapping (user_id to pseudo_id) is computable. The reverse mapping is computationally infeasible. No reverse API. No reverse index. Key material is restricted and audited. Every element of the definition is satisfied. Consumer rights no longer apply to this data, though data minimization and security obligations persist.
Notice what just changed. Under GDPR, the obligations follow the data regardless of how it is keyed. Under the SECURE Data Act, you can use a one-way function precisely because the obligations don’t follow. Same definition. Same data. The architecture diverges at the exact point where obligations either persist or detach.
Let’s see what a pipeline built on this architecture can do.
Data pipeline for personalization
Assume all user behavioral data has been pseudonymized, replacing user_id with pseudo_id. This data trains an ML model indexed by pseudo_id. At inference time, the system performs a forward lookup (user_id to pseudo_id) to select the right model and generate a personalized result.
Consumer experience with pseudonymous ML models
When a consumer opts out of personalization, their data, keyed by pseudo_id, has been exempted from the opt-out, and so makes its way to the ML model. When this opted-out user interacts with the product, the ML model, which continued to be trained on the user’s pseudonymous data, continues to personalize the product for them. The consumer experience is identical to that of a user who never opted out.
Did you notice the difference? Neither did I.
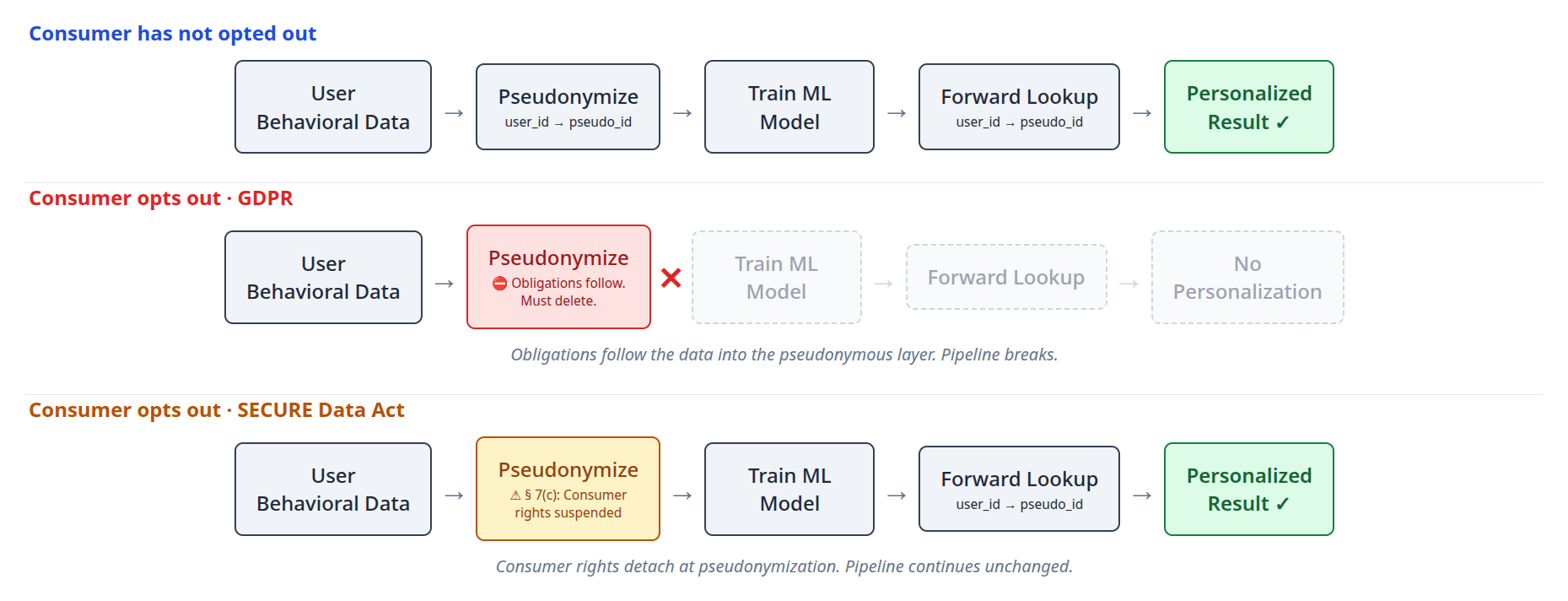
Here is how the bill permits this. At no point was pseudonymous data attributed to an identified person. The system started with a known user and walked forward into the pseudonymous layer. It never walked backward. Forward resolution is not re-identification. The bill’s re-identification provisions contemplate the reverse direction. Forward resolution is simply how a personalization system works. The bill does not address it.
A defender of the bill would point out that the forward lookup operates entirely in the identified layer: the user is logged in, the system derives their pseudo_id from their user_id, and only then touches the pseudonymous data. The pseudonymous data itself is never “attributed to an identified person.” The attribution runs from identity to pseudonym, not the reverse. That reading is consistent with the bill’s text. It is also consistent with a pipeline that delivers personalized content to a known user based on their behavioral history, with the user having no ability to opt out of the data that powers it.
This is not a fantastical architecture. Existing large-scale personalization systems bear more than a passing resemblance to this one. Behavioral features are processed in layers abstracted from direct identity, and identity is resolved at serving time. The SECURE Data Act’s pseudonymous data provisions map onto this existing architecture and exempt its core data processing layer from consumer rights. Other obligations (data minimization, data security) still apply to pseudonymous data. But the consumer-facing rights that would let a user see, delete, or opt out of this processing do not.
How does GDPR handle this?
GDPR treats pseudonymous data as personal data subject to the same constraints as identifiable data. Run the same pipeline under GDPR: the user opts out, and the deletion obligation follows the data into the pseudonymous layer. The controller must locate the user’s pseudo_id, delete the pseudonymous behavioral records, and address any models trained on them. The hair-splitting around one-way mappings and ID resolution at runtime becomes irrelevant to privacy compliance. If the user opts out, all of their data, including pseudonymous data, is in scope.
What follows from the example
GDPR and the SECURE Data Act start from the same sentence and describe the same technical operation: stripping direct identifiers, separating the mapping, applying technical safeguards. The disagreement is about what follows.
GDPR says: the processing is what matters. If you use someone’s behavioral history to target them, they have rights over that processing. It does not matter whether that data is keyed by PII or by a pseudonym. Rights attach to what is done with data.
The SECURE Data Act says: the PII is what matters. Sever the link between personal data and PII through pseudonymization, and the rights detach.
The two frameworks encode different theories of where privacy lives. One locates it in what is done with data. The other locates it in whether the data can be traced back to someone. The same engineer building the same system faces a fundamentally different regulatory question depending on which framework governs. Under GDPR, pseudonymization is a tool you use inside the regulatory perimeter. Under the SECURE Data Act, pseudonymization is the door out of it.