
I am Srikanth Sastry. I am currently an engineering lead at Meta working on privacy infrastructure. Before Meta, I was a software engineer at Google in Cambridge, MA, and before that a postdoctoral associate with Nancy Lynch at CSAIL, MIT. Prior to that, I received my PhD from Texas A&M University.
My professional interests include distributed system design, software engineering processes, and building engineering teams. I also maintain a digital garden — a collection of evolving ideas and notes that complement my blog posts.
In a previous life, during my years in academia, I worked on distributed systems, networking, fault tolerance, and algorithm design and analysis. My list of publications are available on DBLP.
Recent Writing
All 68 posts →
Governance on AI: Mumble incoherently and carry a big stick
A flurry of bills, drafts, and executive orders on AI have dropped across the US and EU. Take a closer look: all this activity is effectively an abdication of governance rather than any constructive scaffolding that could steer AI development and deployment. What we have instead is the heavy hammer of Executive Privilege with limited due process to stop whatever is deemed "unsafe". Here are five examples.

You Don't Have a Relationship with Your LLM. You Have Five.

The Architecture Orphaning Problem with AI Agents

The Guardrail Erosion Problem with AI Agents
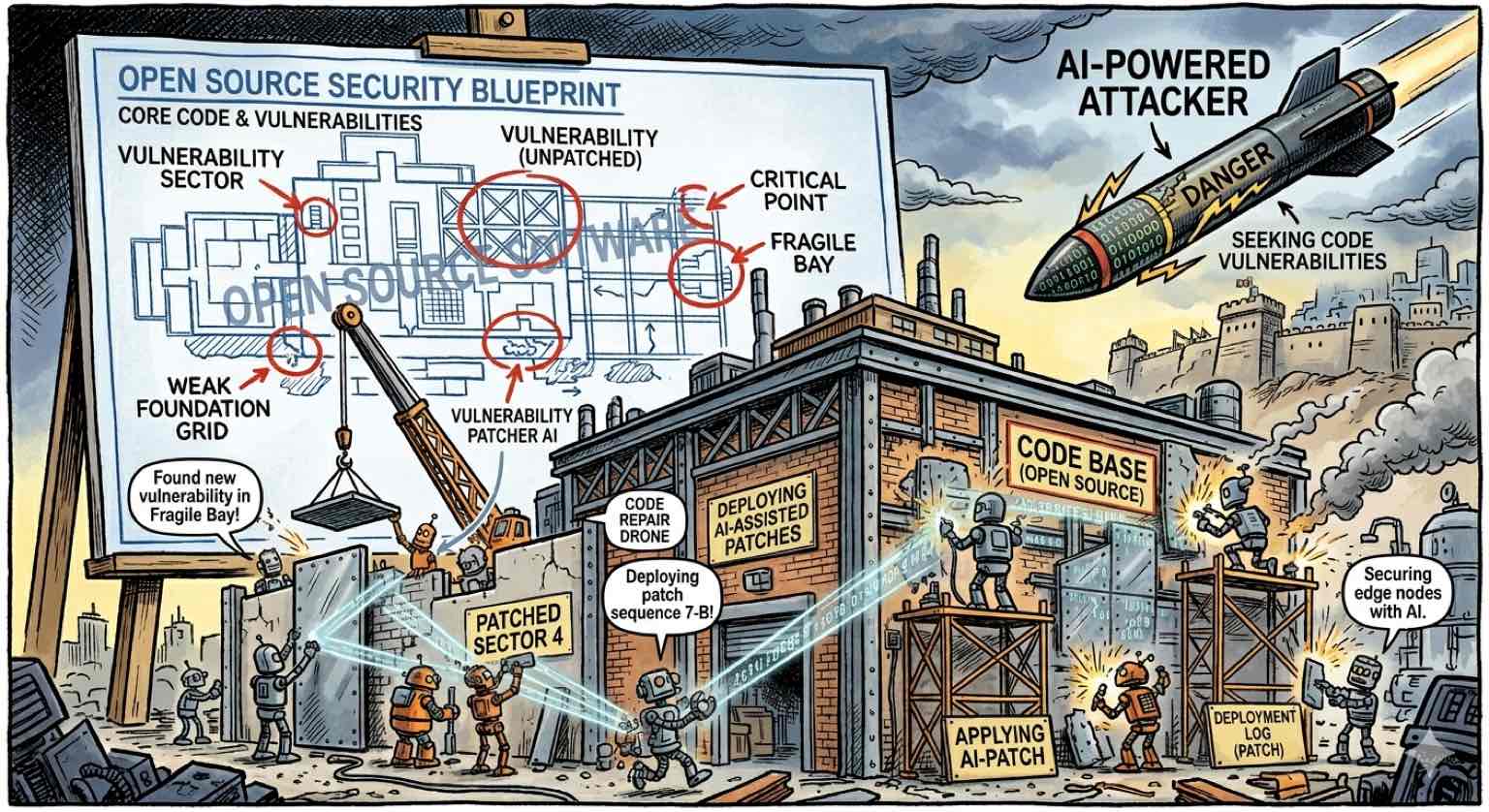
AI vs. Open Source, Part 3: The Constant Eyes

AI vs. Open Source, Part 2: The Hollow Commons

AI vs. Open Source, Part 1: The Empty Grant
From the Garden
All 104 notes →AI Collapses the Economic Moat of Clean-Room Reimplementation
🌳The copyleft moat was never purely legal. It was economic: compliance was cheaper than reimplementation. AI collapsed that cost.
AI Reviewing AI: Shared Blind Spots
🌳AI models reviewing AI-generated code share systematic blind spots with the generator, creating gaps that neither side detects.
AI Security Cost Asymmetry Favors Closed Source
🌳AI equalizes the defender's security cost across open and closed source but varies the attacker's cost by source availability. This inverts Linus's Law.
Align Alerts to SEV Criteria
🌳Alerts should fire at or near the threshold where an SLO breach would occur, not well before.
Architecture Orphaning
🌳Architecture orphaning is the phenomenon where architectural decisions fall between layers that neither specs nor AI agents can govern.
Backward Compatibility for Leaky Abstractions
🌳When a framework leaks implementation details (like serializing arguments at schedule time but loading code from HEAD at execution time), changing a function signature breaks the assumption that old code calls old signatures.
Categorical Ambiguity of AI Agents
🌿AI agents resist relational stabilization because their social cues are rich but inconsistent.
Relational Mode Oscillation in Human-AI Interaction
🌿Users of LLMs unconsciously oscillate between five relational modes — Director, Trainer, Partner, Student, Consumer — within single interactions, often within minutes.